Hiệu suất¶
Hồ sơ¶
Lập hồ sơ là phân tích việc thực hiện một chương trình và đo lường dữ liệu tổng hợp. Những dữ liệu này có thể là thời gian trôi qua của từng hàm, các truy vấn SQL đã thực hiện...
Mặc dù bản thân việc lập hồ sơ không cải thiện hiệu suất của chương trình nhưng nó có thể rất hữu ích trong việc tìm ra các vấn đề về hiệu suất và xác định phần nào của chương trình chịu trách nhiệm cho chúng.
SoOn cung cấp một công cụ lập hồ sơ tích hợp cho phép ghi lại tất cả các truy vấn đã thực hiện và dấu vết ngăn xếp trong quá trình thực thi. Nó có thể được sử dụng để lập hồ sơ một tập hợp các yêu cầu của phiên người dùng hoặc một phần mã cụ thể. Kết quả lập hồ sơ có thể được kiểm tra bằng speedscope ứng dụng nguồn mở tích hợp cho phép hiển thị chế độ xem biểu đồ ngọn lửa hoặc được phân tích bằng các công cụ tùy chỉnh bằng cách trước tiên lưu chúng vào một tệp JSON hoặc trong cơ sở dữ liệu.
Kích hoạt trình hồ sơ¶
Trình lược tả có thể được kích hoạt từ giao diện người dùng, đây là cách dễ nhất để thực hiện điều này nhưng chỉ cho phép lập lược tả các yêu cầu web hoặc từ mã Python, cho phép lập lược tả bất kỳ đoạn mã nào, bao gồm cả các bài kiểm tra.
Trước khi bắt đầu phiên lược tả, trình lược tả phải được bật trên toàn bộ cơ sở dữ liệu. Điều này có thể được thực hiện theo hai cách:
Open the developer mode tools, then toggle the Enable profiling button. A wizard suggests a set of expiry times for the profiling. Click on ENABLE PROFILING to enable the profiler globally.

Đi tới Cài đặt --> Cài đặt chung --> Hiệu suất và đặt thời gian mong muốn cho trường Bật hồ sơ cho đến khi.
After the profiler is enabled on the database, users can enable it on their session. To do so, toggle the Enable profiling button in the developer mode tools again. By default, the recommended options Record sql and Record traces are enabled. To learn more about the different options, head over to Người sưu tầm.
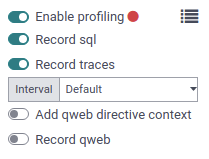
Khi trình lược tả được bật, tất cả các yêu cầu gửi đến máy chủ sẽ được lược tả và lưu vào bản ghi ir.profile. Các bản ghi như vậy được nhóm vào phiên lập hồ sơ hiện tại, kéo dài từ khi trình hồ sơ được bật cho đến khi nó bị tắt.
Ghi chú
Cơ sở dữ liệu trực tuyến của SoOn không thể được lập hồ sơ.
Việc khởi động trình lược tả thủ công có thể thuận tiện cho việc lập cấu hình một phương thức cụ thể hoặc một phần mã. Mã này có thể là một bài kiểm tra, một phương pháp tính toán, toàn bộ quá trình tải, v.v.
Để khởi động trình lược tả từ mã Python, hãy gọi nó là trình quản lý bối cảnh. Bạn có thể chỉ định những gì bạn muốn ghi lại thông qua các tham số. Có một phím tắt để lập hồ sơ các lớp kiểm tra: self.profile(). Xem performance/profiles/collectors để biết thêm thông tin về tham số collectors.
Example
with Profiler():
do_stuff()
Example
with Profiler(collectors=['sql', PeriodicCollector(interval=0.1)]):
do_stuff()
Example
with self.profile():
with self.assertQueryCount(__system__=1211):
do_stuff()
Ghi chú
Trình lược tả được gọi bên ngoài assertQueryCount để nắm bắt các truy vấn được thực hiện khi thoát khỏi trình quản lý bối cảnh (ví dụ: xóa).
Khi trình hồ sơ được bật, tất cả việc thực thi một phương pháp thử nghiệm sẽ được lập hồ sơ và lưu vào bản ghi ir.profile. Những bản ghi như vậy được nhóm lại thành một phiên lập hồ sơ duy nhất. Điều này đặc biệt hữu ích khi sử dụng trang trí @warmup và @users.
Mẹo
Việc phân tích kết quả lập hồ sơ của một phương thức được gọi nhiều lần có thể phức tạp vì tất cả các lệnh gọi được nhóm lại với nhau trong dấu vết ngăn xếp. Thêm ngữ cảnh thực thi làm trình quản lý bối cảnh để chia kết quả thành nhiều khung.
Example
for index in range(max_index):
with ExecutionContext(current_index=index): # Identify each call in speedscope results.
do_stuff()
Phân tích kết quả¶
To browse the profiling results, make sure that the profiler is enabled globally on the
database, then open the developer mode tools and click on the button in the top-right corner of the profiling
section. A list view of the ir.profile records grouped by profiling session opens.
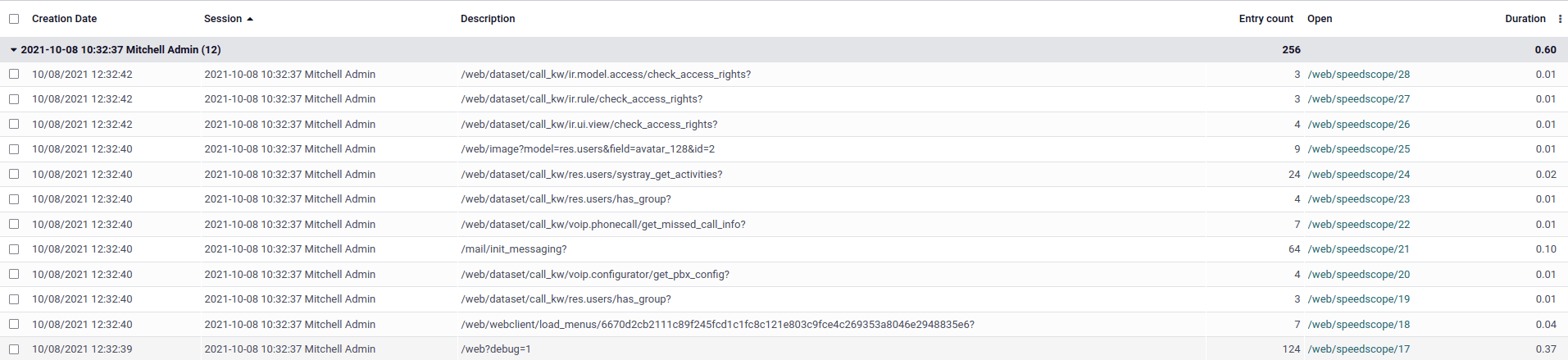
Mỗi bản ghi có một liên kết có thể nhấp vào để mở kết quả kính hiển vi tốc độ trong một tab mới.
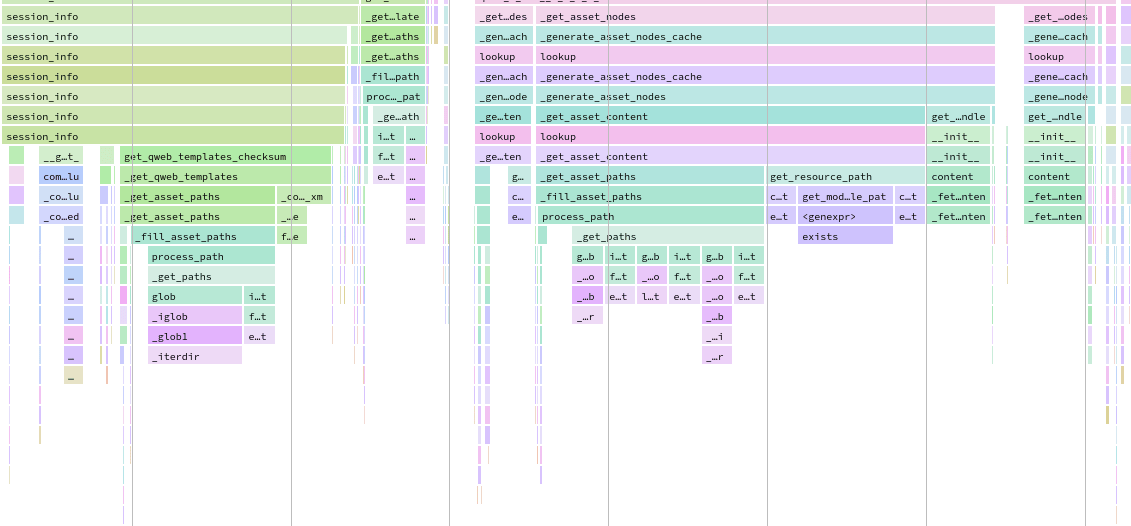
Speedscope nằm ngoài phạm vi của tài liệu này nhưng có rất nhiều công cụ để thử: tìm kiếm, đánh dấu các khung hình tương tự, phóng to khung hình, dòng thời gian, chế độ xem nặng bên trái, chế độ xem bánh sandwich...
Tùy thuộc vào các tùy chọn lập hồ sơ đã được kích hoạt, SoOn tạo ra các chế độ xem khác nhau mà bạn có thể truy cập từ menu trên cùng.
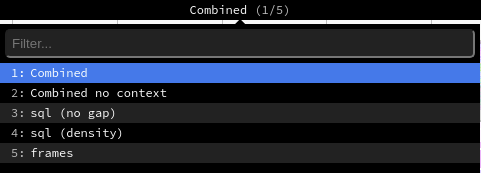
Chế độ xem Combined hiển thị tất cả các truy vấn SQL và dấu vết được hợp nhất với nhau.
Chế độ xem Combined no context hiển thị kết quả tương tự nhưng bỏ qua bối cảnh thực thi đã lưu <performance/profiling/enable>`.
Chế độ xem sql (no Gap) hiển thị tất cả các truy vấn SQL như thể chúng được thực thi lần lượt mà không có bất kỳ logic Python nào. Điều này chỉ hữu ích cho việc tối ưu hóa SQL.
Chế độ xem sql (mật độ) chỉ hiển thị tất cả các truy vấn SQL, để lại khoảng cách giữa chúng. Điều này có thể hữu ích để phát hiện xem mã SQL hoặc Python nào có phải là vấn đề hay không và để xác định các vùng có thể phân nhóm nhiều truy vấn nhỏ.
Chế độ xem frames chỉ hiển thị kết quả của bộ sưu tập định kỳ.
Quan trọng
Mặc dù trình lược tả đã được thiết kế nhẹ nhất có thể nhưng nó vẫn có thể ảnh hưởng đến hiệu suất, đặc biệt là khi sử dụng Sync Collector. Hãy ghi nhớ điều đó khi phân tích kết quả của kính hiển vi tốc độ.
Người sưu tầm¶
Trong khi trình lập hồ sơ quan tâm đến thời điểm lập hồ sơ, thì người thu thập sẽ quan tâm đến cái gì.
Each collector specializes in collecting profiling data in its own format and manner. They can be individually enabled from the user interface through their dedicated toggle button in the developer mode tools, or from Python code through their key or class.
Hiện tại có bốn nhà sưu tập có sẵn trong SoOn:
Tên |
Nút bật tắt |
Khóa Python |
Lớp Python |
|---|---|---|---|
Ghi sql |
|
|
|
Bộ sưu tập định kỳ |
Ghi lại dấu vết |
|
|
Ghi qweb |
|
|
|
Trình thu thập đồng bộ |
KHÔNG |
|
|
Theo mặc định, trình lược tả kích hoạt SQL và bộ sưu tập định kỳ. Cả khi nó được kích hoạt từ giao diện người dùng hoặc mã Python.
Trình thu thập SQL¶
Trình thu thập SQL lưu tất cả các truy vấn SQL được thực hiện vào cơ sở dữ liệu trong luồng hiện tại (đối với tất cả các con trỏ), cũng như dấu vết ngăn xếp. Chi phí chung của bộ sưu tập được thêm vào luồng được phân tích cho mỗi truy vấn, điều đó có nghĩa là việc sử dụng nó trên nhiều truy vấn nhỏ có thể ảnh hưởng đến thời gian thực hiện và các trình phân tích hồ sơ khác.
Nó đặc biệt hữu ích để gỡ lỗi số lượng truy vấn hoặc thêm thông tin vào Periodic Collector trong chế độ xem speedscope kết hợp.
Bộ sưu tập định kỳ¶
Bộ sưu tập này chạy trong một luồng riêng biệt và lưu dấu vết ngăn xếp của luồng được phân tích ở mỗi khoảng thời gian. Khoảng thời gian (theo mặc định là 10 mili giây) có thể được xác định thông qua tùy chọn Interval trong giao diện người dùng hoặc tham số interval trong mã Python.
Cảnh báo
Nếu khoảng thời gian được đặt ở giá trị rất thấp, việc lập hồ sơ các yêu cầu dài sẽ tạo ra các vấn đề về bộ nhớ. Nếu khoảng thời gian được đặt ở giá trị rất cao, thông tin về việc thực thi hàm ngắn sẽ bị mất.
Đây là một trong những cách tốt nhất để phân tích hiệu suất vì nó có tác động rất thấp đến thời gian thực hiện nhờ có luồng riêng biệt.
Bộ sưu tập QWeb¶
Bộ sưu tập này tiết kiệm thời gian thực thi Python và các truy vấn của tất cả các lệnh. Đối với SQL Collector, chi phí hoạt động có thể quan trọng khi thực thi nhiều lệnh nhỏ. Các kết quả này khác với các trình thu thập khác về mặt dữ liệu được thu thập và có thể được phân tích từ chế độ xem biểu mẫu ir.profile bằng cách sử dụng tiện ích tùy chỉnh.
Nó chủ yếu hữu ích để tối ưu hóa lượt xem.
Trình thu thập đồng bộ hóa¶
Trình thu thập này lưu ngăn xếp cho mọi lệnh gọi và trả về của hàm và chạy trên cùng một luồng, điều này ảnh hưởng lớn đến hiệu suất.
Việc gỡ lỗi và hiểu các luồng phức tạp cũng như thực hiện chúng trong mã có thể sẽ hữu ích. Tuy nhiên, nó không được khuyến khích để phân tích hiệu suất vì chi phí cao.
Cạm bẫy hiệu suất¶
Hãy cẩn thận với sự ngẫu nhiên. Nhiều lần thực thi có thể dẫn đến các kết quả khác nhau. Ví dụ: trình thu gom rác được kích hoạt trong quá trình thực thi.
Hãy cẩn thận với việc chặn cuộc gọi. Trong một số trường hợp,
c_callbên ngoài có thể mất một chút thời gian trước khi giải phóng GIL, do đó dẫn đến các khung hình dài không mong muốn với Periodic Collector. Điều này sẽ được trình hồ sơ phát hiện và đưa ra cảnh báo. Có thể kích hoạt trình hồ sơ theo cách thủ công trước các cuộc gọi như vậy nếu cần.Hãy chú ý đến bộ đệm. Việc lập hồ sơ trước đó
view/assets/... nằm trong bộ đệm có thể dẫn đến các kết quả khác nhau.Hãy nhận biết chi phí của hồ sơ. Chi phí của SQL Collector có thể quan trọng khi có nhiều truy vấn nhỏ được thực thi. Lập hồ sơ là cách thiết thực để phát hiện sự cố nhưng bạn có thể muốn tắt trình phân tích hồ sơ để đo lường tác động thực sự của việc thay đổi mã.
Kết quả hồ sơ có thể tốn nhiều bộ nhớ. Trong một số trường hợp (ví dụ: lập hồ sơ cài đặt hoặc yêu cầu dài), có thể bạn đạt đến giới hạn bộ nhớ, đặc biệt là khi hiển thị kết quả speedscope, điều này có thể dẫn đến lỗi HTTP 500. Trong trường hợp này, bạn có thể cần khởi động máy chủ với giới hạn bộ nhớ cao hơn:
--limit-memory-hard $((8*1024**3)).
Dân số cơ sở dữ liệu¶
SoOn CLI cung cấp tính năng dân số cơ sở dữ liệu thông qua lệnh CLI odoo-bin populate.
Thay vì hướng dẫn sử dụng tẻ nhạt hoặc đặc tả dữ liệu thử nghiệm theo chương trình, người ta có thể sử dụng tính năng này để điền vào cơ sở dữ liệu theo yêu cầu số lượng dữ liệu thử nghiệm mong muốn. Điều này có thể được sử dụng để phát hiện các lỗi khác nhau hoặc các vấn đề về hiệu suất trong các luồng được thử nghiệm.
Để điền vào một mô hình nhất định, có thể xác định các phương thức và thuộc tính sau.
Ghi chú
Bạn phải xác định ít nhất _populate() hoặc _populate_factories() trên mô hình để kích hoạt tập hợp cơ sở dữ liệu.
Example
from odoo.tools import populate
class CustomModel(models.Model)
_inherit = "custom.some_model"
_populate_sizes = {"small": 100, "medium": 2000, "large": 10000}
_populate_dependencies = ["custom.some_other_model"]
def _populate_factories(self):
# Record ids of previously populated models are accessible in the registry
some_other_ids = self.env.registry.populated_models["custom.some_other_model"]
def get_some_field(values=None, random=None, **kwargs):
""" Choose a value for some_field depending on other fields values.
:param dict values:
:param random: seeded :class:`random.Random` object
"""
field_1 = values['field_1']
if field_1 in [value2, value3]:
return random.choice(some_field_values)
return False
return [
("field_1", populate.randomize([value1, value2, value3])),
("field_2", populate.randomize([value_a, value_b], [0.5, 0.5])),
("some_other_id", populate.randomize(some_other_ids)),
("some_field", populate.compute(get_some_field, seed="some_field")),
('active', populate.cartesian([True, False])),
]
def _populate(self, size):
records = super()._populate(size)
# If you want to update the generated records
# E.g setting the parent-child relationships
records.do_something()
return records
Công cụ dân số¶
Nhiều công cụ dân số có sẵn để dễ dàng tạo các trình tạo dữ liệu cần thiết.
Thực hành tốt¶
Hoạt động hàng loạt¶
Khi làm việc với các tập bản ghi, các thao tác hàng loạt hầu như luôn luôn tốt hơn.
Example
Không gọi phương thức chạy truy vấn SQL trong khi lặp qua một tập bản ghi vì nó sẽ làm như vậy đối với từng bản ghi của tập hợp.
def _compute_count(self):
for record in self:
domain = [('related_id', '=', record.id)]
record.count = other_model.search_count(domain)
Thay vào đó, hãy thay thế search_count bằng _read_group để thực thi một truy vấn SQL cho toàn bộ lô bản ghi.
def _compute_count(self):
domain = [('related_id', 'in', self.ids)]
counts_data = other_model._read_group(domain, ['related_id'], ['__count'])
mapped_data = dict(counts_data)
for record in self:
record.count = mapped_data.get(record, 0)
Ghi chú
Ví dụ này không tối ưu và cũng không đúng trong mọi trường hợp. Nó chỉ thay thế cho search_count. Một giải pháp khác có thể là tìm nạp trước và đếm trường One2many nghịch đảo.
Example
Đừng tạo các bản ghi lần lượt.
for name in ['foo', 'bar']:
model.create({'name': name})
Thay vào đó, hãy tích lũy các giá trị tạo và gọi phương thức create trên lô. Làm như vậy hầu như không có tác động gì và giúp khung tối ưu hóa việc tính toán các trường.
create_values = []
for name in ['foo', 'bar']:
create_values.append({'name': name})
records = model.create(create_values)
Example
Không thể tìm nạp trước các trường của tập bản ghi trong khi duyệt một bản ghi trong vòng lặp.
for record_id in record_ids:
model.browse(record_id)
record.foo # One query is executed per record.
Thay vào đó, hãy duyệt toàn bộ tập bản ghi trước.
records = model.browse(record_ids)
for record in records:
record.foo # One query is executed for the entire recordset.
Chúng tôi có thể xác minh rằng các bản ghi được tìm nạp trước theo đợt bằng cách đọc trường prefetch_ids bao gồm từng id bản ghi. Việc duyệt tất cả các bản ghi cùng nhau là không thực tế,
Nếu cần, phương thức with_prefetch có thể được sử dụng để tắt tính năng tìm nạp trước hàng loạt:
for values in values_list:
message = self.browse(values['id']).with_prefetch(self.ids)
Giảm độ phức tạp của thuật toán¶
Độ phức tạp của thuật toán là thước đo thời gian hoàn thành một thuật toán đối với kích thước n của đầu vào. Khi độ phức tạp cao, thời gian thực hiện có thể tăng nhanh khi đầu vào trở nên lớn hơn. Trong một số trường hợp, độ phức tạp của thuật toán có thể được giảm bớt bằng cách chuẩn bị dữ liệu đầu vào một cách chính xác.
Example
Đối với một vấn đề nhất định, hãy xem xét một thuật toán đơn giản được tạo bằng hai vòng lặp lồng nhau có độ phức tạp là O(n²).
for record in self:
for result in results:
if results['id'] == record.id:
record.foo = results['foo']
break
Giả sử rằng tất cả các kết quả đều có id khác nhau, chúng ta có thể chuẩn bị dữ liệu để giảm độ phức tạp.
mapped_result = {result['id']: result['foo'] for result in results}
for record in self:
record.foo = mapped_result.get(record.id)
Example
Việc chọn cấu trúc dữ liệu xấu để giữ đầu vào có thể dẫn đến độ phức tạp bậc hai.
invalid_ids = self.search(domain).ids
for record in self:
if record.id in invalid_ids:
...
Nếu invalid_ids là cấu trúc dữ liệu giống danh sách, thì độ phức tạp của thuật toán có thể là bậc hai.
Thay vào đó, hãy ưu tiên sử dụng các thao tác tập hợp như truyền invalid_ids vào một tập hợp.
invalid_ids = set(invalid_ids)
for record in self:
if record.id in invalid_ids:
...
Tùy thuộc vào đầu vào, các thao tác trên tập bản ghi cũng có thể được sử dụng.
invalid_ids = self.search(domain)
for record in self - invalid_ids:
...
Sử dụng chỉ mục¶
Các chỉ mục cơ sở dữ liệu có thể giúp đẩy nhanh các hoạt động tìm kiếm, có thể là từ tìm kiếm trong hoặc thông qua giao diện người dùng.
name = fields.Char(string="Name", index=True)
Cảnh báo
Hãy cẩn thận để không lập chỉ mục cho mọi trường vì các chỉ mục tiêu tốn dung lượng và ảnh hưởng đến hiệu suất khi thực thi một trong các INSERT, UPDATE và DELETE.